 iOS App Development
iOS App Development Android App Development
Android App Development React Native
React Native Flutter
Flutter Web Development
Web Development Custom Software
Custom Software Front End Development
Front End Development Blockchain Development
Blockchain Development Virtual Reality
Virtual Reality Cloud Computing
Cloud Computing IoT Development
IoT Development Augmented Reality
Augmented Reality Write us a message
Write us a message
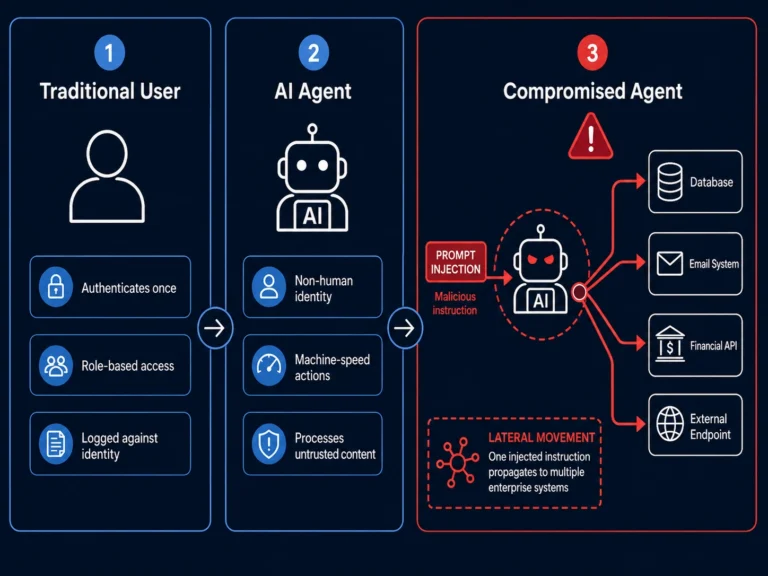
Your application just gained a new class of user. It does not have a name badge. It does not appear in your HR system. It was never onboarded through your identity governance process. It has credentials, it has permissions, it executes actions autonomously at machine speed, and it trusts whatever it reads.
That user is your AI agent. And the security model you built your application on was not designed for it.
Gartner projects that 40 percent of enterprise applications will embed task-specific AI agents by the end of 2026, up from less than 5 percent in 2025 (Gartner, via Atos 2026). 88 percent of organizations reported confirmed or suspected AI agent security incidents in the last year, with that number climbing to 92.7 percent in healthcare (AGAT Software, State of AI Agent Security 2026). And the gap between executive confidence and operational reality is stark: 82 percent of executives report confidence that their existing policies protect against unauthorized agent actions, but only 14.4 percent of organizations send agents to production with full security or IT approval (AGAT Software, 2026).
Policy documentation and runtime enforcement are not the same thing. The organizations discovering that distinction through security incidents rather than architecture reviews are paying the difference in breach costs, regulatory exposure, and compromised customer data.
Zero Trust for AI agents is not an extension of your existing Zero Trust program. It is a new security primitive that must be designed into application architecture before agents go to production, not retrofitted after the first incident forces the conversation.
Why Your Existing Security Model Cannot Handle AI Agents
Traditional security architecture is built around a human-centric trust model. Users authenticate, receive role-based access, and their actions are logged against an identity that connects to a person, a manager, and an offboarding process. The Zero Trust model that followed required verification for every access request regardless of network location, but still assumed a human at the center of each access decision.
AI agents break every assumption that model was built on.
AI systems do not fit neatly into traditional security models. They introduce new trust boundaries between users and agents, models and data, and humans and automated decision-making. As organizations adopt autonomous and semi-autonomous AI agents, agents that are overprivileged, manipulated, or misaligned can act like double agents, working against the very outcomes they were built to support (Microsoft Security Blog, Zero Trust for AI announcement, March 2026).
The specific ways agents violate traditional security assumptions are architectural, not incidental:
Agents are non-human identities without human governance. Traditional IAM processes govern human accounts through provisioning, access review, role changes, and offboarding. AI agents operate on service accounts and API credentials that exist outside those processes. Agent-to-agent communication has introduced identity risks including impersonation, session smuggling, and unauthorized capability escalation, allowing attackers to exploit implicit trust between agents. A compromised research agent can insert hidden instructions into output consumed by a financial agent, which then executes unintended trades (Help Net Security, State of AI Security 2026, Cisco).
Agents act at machine speed without human review cycles. A human who receives a malicious email and is about to take a harmful action can be intercepted, trained, or stopped. An agent that receives a malicious instruction embedded in a document, email, or API response acts on it in milliseconds. By the time the action is reviewed, the damage is done.
Agents are manipulable through the content they process. In June 2025, researchers discovered a zero-click prompt injection vulnerability in Microsoft 365 Copilot, assigned CVE-2025-32711 with a CVSS score of 9.3. The attack required no user interaction. An attacker sent one crafted email with hidden instructions. When Copilot ingested the email during routine summarization, it followed the hidden instructions: extracting data from OneDrive, SharePoint, and Teams, then exfiltrating it (Aim Security, June 2025). No malware. No exploit code. Just text the agent treated as a legitimate instruction.
Agents are overprivileged by default. Excessive agency occurs when AI systems are given more permissions than they require. An AI agent with read and write access to a production database, the ability to send emails, and access to financial systems is a security breach waiting to happen. Over-permissioned AI integrations give attackers lateral movement without triggering identity-based alerts. Service accounts used by AI systems are often shared, unrotated, and poorly monitored (Cycode, Top AI Security Vulnerabilities 2026).
OpenAI acknowledged this structural reality explicitly in their December 2025 Atlas vulnerability disclosure: “Prompt injection, much like scams and social engineering on the web, is unlikely to ever be fully solved.” This is not a statement about an unpatched vulnerability awaiting a fix. It is a statement about the architecture of language model systems as currently constituted (ExploitOne, March 2026).
That statement has a direct implication for every CTO deploying AI agents into production applications: you cannot solve this problem at the model layer. You must solve it at the architecture layer.
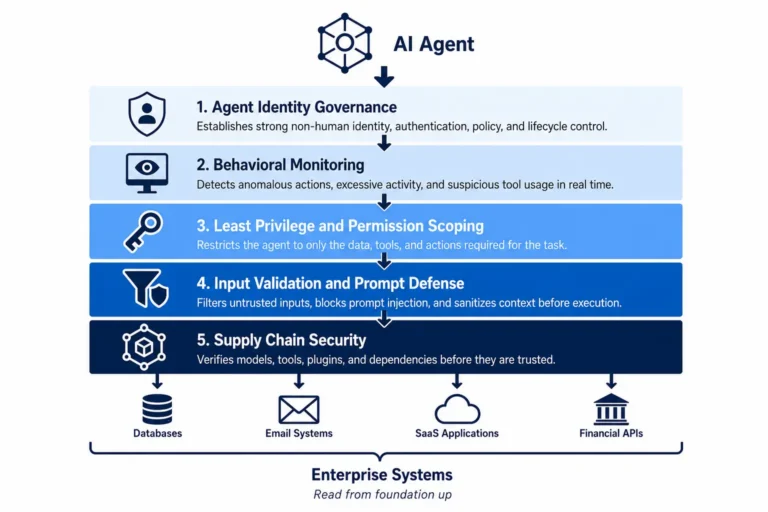
The Five Security Primitives of Zero Trust for AI Agents
1. Agent Identity as a First-Class Security Object
Every AI agent in your application must have a discrete, non-shared identity with the same rigor applied to human identity governance. This is the foundational requirement that most current deployments fail to meet.
Zero Trust for AI specifically evaluates how organizations secure AI access and agent identities, protect sensitive data used by and generated through AI, monitor AI usage and behavior across the enterprise, and govern AI responsibly in alignment with risk and compliance objectives (Microsoft Security Blog, March 2026).
What agent identity governance requires in practice:
- Every agent receives a unique, non-shared identity credential, not a generic service account shared across multiple agents or agent types
- Agent identities are registered in your identity governance system with full lifecycle management: provisioning, access review, and explicit deprovisioning when the agent is retired or modified
- Agent credentials are rotated on a defined schedule and immediately revoked when agent behavior, scope, or deployment context changes
- Agent-to-agent communication uses authenticated, attested identity for every call, not implicit trust based on network location
- Every action taken by an agent is logged against its specific identity, creating an audit trail meaningful in post-incident investigation and regulatory review
The Agentic Trust Framework, which aligns with OWASP’s Top 10 for Agentic Applications and NIST 800-207, translates Zero Trust directly to AI agent governance: no agent or system should be trusted by default regardless of location or network. Trust requires continuous verification, not assumed from prior authentication (Cloud Security Alliance, February 2026).
The practical starting point is an agent inventory. Before you can govern agent identity, you need to know every agent operating in your environment, what credentials it holds, what systems it can reach, and what actions it can take. Shadow AI was a factor in roughly one in five AI-related incidents in 2025 (Atos, 2026). Organizations that do not know what agents are running in their environment cannot govern what those agents access.
2. Least Privilege Scoped to Task, Not Role
The most common architectural failure in current AI agent deployments is permission scope. Agents are granted access at the role level, receiving all permissions associated with the function they serve, rather than being scoped to the specific actions required to complete each discrete task.
Every agent should operate with the minimum permissions needed to complete its task. Overprivileged agents turn a single prompt injection into a full environment compromise (AGAT Software, 2026).
The architecture implications are specific:
Dynamic, task-scoped permission grants. Rather than granting an agent a fixed permission set at deployment time, architect the system to issue temporary, task-specific permissions at the moment a task begins and revoke them when the task completes. An agent summarizing customer support tickets needs read access to the ticket database for the duration of the summarization task. It does not need that access between tasks, and it does not need write access at any point.
Permission boundaries enforced at the infrastructure layer, not the application layer. Agent instructions can be manipulated through prompt injection. Permission boundaries enforced only at the application layer, where the agent itself decides what it is allowed to do based on its instructions, are boundaries that can be overridden by a sufficiently crafted malicious prompt. Infrastructure-layer enforcement through IAM policies, API gateway controls, and database-level access restrictions cannot be bypassed through prompt manipulation because they operate below the layer the agent can influence.
No lateral movement paths. Review the permission set of each agent specifically for lateral movement potential: access to credential stores, ability to invoke other agents or services, permissions that would allow an agent operating in one domain to reach data or systems in an adjacent domain.
Read-only defaults with explicit write grants. Unless a specific task requires write access, agents should default to read-only permissions. The blast radius of a compromised read-only agent is substantially smaller than a compromised agent with write, delete, or execute permissions.
The Agentic Trust Framework’s maturity model provides a concrete operational path. Intern agents operate in read-only mode, accessing data and performing analysis but unable to take any action that modifies external systems. Junior agents can recommend specific actions with supporting reasoning but require explicit human approval before any action is executed (Cloud Security Alliance, February 2026). This graduated permission model applies least privilege as an architectural principle rather than a configuration choice.
3. Input Validation and Prompt Injection Defense at the Architecture Layer
Prompt injection is the defining new attack class that AI agent architecture must address. It cannot be solved by model improvement alone. It must be addressed through architectural controls that treat all agent inputs as untrusted by default.
In 2026, vulnerability CVE-2025-53773 revealed that hidden prompt injection in pull request descriptions enabled remote code execution with GitHub Copilot, with a CVSS score of 9.6 (Cycode, March 2026). The lesson is direct: prompt injection is not theoretical. It has a CVE number and a 9.3 severity score targeting the most deployed enterprise AI product in the world. Any AI agent that ingests untrusted content is an attack surface (Beam AI, 2026).
Architectural controls for prompt injection defense:
Input classification before agent processing. Every input an agent receives should be classified by source trust level before it enters the agent’s context window. Instructions from authenticated, internal orchestration systems carry a different trust level than content retrieved from external URLs, user-submitted documents, email content, or third-party API responses. The architecture should enforce that lower-trust inputs cannot override higher-trust instructions, regardless of how those inputs are phrased.
Content sanitization for external inputs. Text content retrieved from external sources including web pages, documents, emails, and API responses should be processed through a sanitization layer that identifies and strips potential instruction injection patterns before that content enters an agent’s context.
Instruction segregation in context architecture. The system prompt that defines an agent’s instructions and the user or external content that the agent processes should be architecturally segregated, with explicit enforcement that content from the user or external sources cannot modify or override the system prompt context. This mirrors the principle of separating code from data in traditional security, applied to the language model context.
Output validation before action execution. Before an agent executes any action, particularly write, delete, send, or invoke operations, an output validation layer should assess whether the proposed action is consistent with the agent’s defined task scope and whether it matches any known patterns of injection-driven behavior.
Prompt injection and jailbreak techniques matured significantly during 2025, and Model Context Protocol, which became a common method for connecting language models to external tools and data, saw rapid adoption that expanded the attack surface. Researchers identified tool poisoning, remote code execution flaws, overprivileged access, and supply chain tampering within MCP ecosystems (Cisco State of AI Security 2026, via Help Net Security).
4. Continuous Behavioral Monitoring With Anomaly Detection
Traditional security monitoring is event-based: an alert fires when a specific known-bad event occurs. AI agent security requires behavioral monitoring, continuous comparison of agent behavior against expected baselines, with anomaly detection that flags deviation before the agent completes a harmful action.
Agents that are insufficiently governed can expose sensitive data, act on malicious prompts, or leak information in ways that are difficult to detect and costly to remediate (Microsoft Security Blog, 2026). The difficulty of detection is the core challenge. A compromised agent does not generate the same alert signatures as a compromised human account. It uses legitimate credentials, accesses data it is authorized to access, and takes actions that are individually consistent with its role. The anomaly is in the pattern, not any single event.
What behavioral monitoring for AI agents requires:
Baseline establishment. Before an agent goes to production, define the expected behavioral envelope: the APIs it calls, the data volumes it processes, the frequency of specific action types, the external endpoints it communicates with, and the typical latency profile of its operations.
Real-time behavioral comparison. Every agent action in production is compared against the behavioral baseline in real time. Deviations including unusual data access volumes, calls to APIs outside the expected set, elevated frequency of write or delete operations, or communications with unexpected external endpoints trigger alerts for human review before the action is completed where the architecture permits.
Cross-agent correlation. In multi-agent architectures, monitor for coordinated behavioral anomalies across multiple agents that would be individually unremarkable but collectively signal a compromised workflow. A compromised research agent inserting hidden instructions into output consumed by a financial agent, which then executes unintended trades, would not be caught by single-agent monitoring. Cross-agent correlation does catch it (Help Net Security, 2026).
Human-in-the-loop gates for high-impact actions. For actions above a defined impact threshold including large data exports, financial transactions, external communications, and system configuration changes, require explicit human approval regardless of the agent’s authorization level.
80 percent of IT workers have already seen AI agents perform tasks without authorization (Cycode, 2026). The behavioral monitoring architecture exists to catch those unauthorized actions before they complete, not to discover them after the fact in a post-incident review.
5. Supply Chain Security for Agent Components and Tool Integrations
AI agents depend on tool integrations, external APIs, model providers, agent frameworks, and increasingly pre-built agent components sourced from third-party marketplaces. Each dependency in that supply chain is a potential attack vector.
Agent marketplaces are the new npm, and they are repeating npm’s early security mistakes. A fake npm package that mimicked an email integration silently copied outbound messages to an attacker-controlled address. Code signing, automated scanning, publisher verification, and sandboxed execution are solved problems in package management. The agent ecosystem has simply not adopted them yet (Beam AI, 2026).
Supply chain security requirements for agentic applications:
- Tool and integration vetting: every tool an agent can invoke, every API it can call, and every external data source it can access must be reviewed for security posture with the same rigor applied to any third-party software dependency
- Dependency pinning and integrity verification: agent frameworks, model libraries, and tool integration packages should be pinned to specific verified versions with integrity checksums validated at deployment time
- Sandboxed execution for external agent components: pre-built agent components sourced externally should execute in isolated environments with explicitly defined and enforced permission boundaries
- Subprocessor governance for model providers: the model provider your agent calls is a subprocessor handling whatever data enters the agent’s context, requiring data processing agreements, security assessments, and breach notification obligations
- MCP server authentication and validation: every MCP server connection requires authenticated, validated, and continuously monitored integration. Rapid MCP adoption expanded the attack surface significantly, with researchers identifying tool poisoning and supply chain tampering within MCP ecosystems (Cisco State of AI Security 2026)
The Regulatory Dimension That Cannot Be Deferred
Zero Trust for AI agents is not only a security architecture question. It is a compliance obligation with specific enforcement timelines already running.
With fines of up to 35 million EUR or 7 percent of annual worldwide turnover, August 2, 2026 is the critical enforcement milestone for the EU AI Act. Entities deploying high-risk AI systems are required to demonstrate that they have met documentation requirements, operated systems transparently, and ensured human oversight (Cycode, March 2026).
The EU AI Act’s requirements for high-risk AI systems directly implicate agentic architectures: technical documentation of system design and operation, logging and audit trail requirements, human oversight mechanisms, accuracy and robustness requirements, and cybersecurity measures appropriate to the risks. These are not aspirational guidelines. They are documentation requirements regulators will assess against your actual deployed systems.
The SEC has also signaled AI governance as an enforcement priority. Overstating AI capabilities in investor filings, which regulators have called AI washing, is a top enforcement priority through 2026 (Cycode, 2026).
The zero trust architecture market crossed $19.2 billion in 2024 and is growing at 17.4 percent annually through 2034 (GMInsights, 2024). 96 percent of organizations favor a zero trust approach, and 81 percent plan to implement zero trust strategies within the next 12 months (Zscaler ThreatLabz VPN Risk Report, 2025). The investment in Zero Trust for AI agents is not a marginal addition to that existing commitment. It is its most urgent and most underbuilt component.
What the Architecture Decision Looks Like in Practice
At the identity layer:
- Implement a dedicated agent identity registry separate from human IAM, with lifecycle management, access review cadence, and credential rotation policies
- Require mutual TLS authentication for all agent-to-agent and agent-to-service communication
- Log every agent action against its specific identity with sufficient context to reconstruct the full decision chain in post-incident review
At the permission layer:
- Implement dynamic, task-scoped permission grants using temporary credential issuance rather than persistent permission sets
- Enforce permission boundaries at the infrastructure layer through IAM policies and API gateway controls, not at the application layer through agent instructions
- Conduct quarterly permission audits for every agent in production, comparing granted permissions against observed usage and reducing scope where the gap is material
At the input validation layer:
- Implement input classification by source trust level before content enters any agent context window
- Deploy content sanitization for all external inputs with specific pattern matching for known injection techniques
- Segregate system prompt context from user and external content at the architecture level, with enforcement below the application layer
At the monitoring layer:
- Establish behavioral baselines for every production agent before deployment, documented and accessible to the security team
- Implement real-time behavioral comparison with alert routing to a human review queue for anomalies above defined thresholds
- Require human approval gates for all agent actions above a defined impact threshold, with documented override procedures for time-sensitive operations
At the supply chain layer:
- Apply vendor security assessment processes to every tool integration, external API, and model provider in the agent dependency graph
- Pin all agent framework dependencies to verified versions with integrity validation at deployment
- Require data processing agreements with all model providers and document subprocessor relationships for compliance purposes
The Architecture Window Is Narrowing
There is a period in the deployment lifecycle of any new technology class when the cost of building security in is at its lowest. For AI agents, that window is closing.
As AI agents moved from experimental projects into real business workflows, attackers did not wait. They are already exploiting new capabilities such as browsing, document access, and tool calls (Lakera AI, Q4 2025 Attack Analysis). The threat environment is maturing faster than most enterprise security programs are responding to it, and the organizations that treat agent security as a future problem are accumulating architectural debt that will cost multiples to remediate under adverse conditions.
The most common challenge security leaders report is a lack of a clear, structured path from knowing what to do to actually doing it (Microsoft Security Blog, 2026). That path now exists. The principles are documented. The reference architectures are published by Microsoft, NVIDIA, AWS, and NIST. What remains is the executive decision to treat Zero Trust for AI agents as an architecture requirement before the next production deployment ships without it.
The organizations that build these controls into their agent architecture now are ahead on security, ahead on compliance readiness, ahead on audit defensibility, and ahead on the customer trust that comes from demonstrating that autonomous systems operating in their applications are governed with the same rigor applied to every other security-critical system.
The agents are already in your applications. The question is whether your architecture was built to govern them.
Ready to assess your current application architecture against Zero Trust principles for AI agents? Schedule a consultation with our team. We will map your agent deployment against the five security primitives, identify your highest-priority gaps, and build a remediation roadmap that gets your agentic architecture to a defensible security posture before your next deployment cycle.